Why choose ChatGPT for localization?
The localization industry is well familiar with the limitations of machine translation (MT) and AI translation tools since they’re not a new concept. The tools translate sentence by sentence without taking context into consideration, fail to provide relevant analogies for foreign cultures, misuse genders, or inappropriately use idioms in specific situations, to name just a few issues.
While machine translation tools based on neural networks like Google Translate, Amazon Translate, or DeepL are subject to these limitations, giant language models like ChatGPT can tackle these problems because they possess the ability to reflect relevant literature and context. Additionally, they can enhance the task of translating content by considering style, length limits, ignoring mistakes, or detecting unknown words.
When applied with this in mind, LLMs, such as ChatGPT, can already produce high-quality machine translation results and prove valuable in guiding post-editing efforts.
However, ChatGPT can’t generate translations in word-by-word mode. Therefore, giving them prompts like “Translate the following text <#>” will likely yield results similar to DeepL or potentially worse.
ChatGPT requires multiple instructions to scrutinize the text first, retrieve relevant context, come up with alternatives in other languages, and then translate using all this information. This process results in higher-quality outcomes.
It may seem daunting and impractical for large volumes of content where you can’t afford to chat with AI about every single string. But there’s good news. It can be automated, minimizing effort by applying necessary steps at scale and without manual intervention.
When considering these characteristics, Large Language Models represent tremendous opportunities for accelerating and increasing the productivity of content creation and localization workflows.
Ability to execute across the localization process
The impact on the productivity of ChatGPT is multiplied by its ability to be used for multiple tasks across the localization workflow. While AI translation tools are mostly capable of translating, ChatGPT can be applied in various steps of the localization process:
- Source text proofreading: ChatGPT can identify and correct errors or suggest improvements, ensuring the accuracy and quality of the original content.
- Pre-translation: ChatGPT can be employed for pre-translation tasks, generating initial translations instantly and providing a foundation for further refinement by human translators or checking the localization setup by developers.
- Alternative suggestions: By leveraging its vast language knowledge, ChatGPT can propose different phrasing or wording choices, enabling translators to explore various options and select the most appropriate one.
- Post-editing preparation: ChatGPT can assist in the preparation of post-editing tasks. It can help identify sections of the translated content that may require additional attention or refinement, helping post-editors determine what to focus on.
- Content generation: ChatGPT can be utilized for content creation during the localization process, such as materials for translators, product descriptions, or user interface elements, reducing the time and effort required for manual content creation.
- Localization QA: Spell and grammar checks, length checks, missing tags, symbols, or special characters — all these can be analyzed by ChatGPT, which can then also suggest improvements in the output format that QA teams can easily incorporate.
Achieving meaningful results from ChatGPT
To obtain meaningful results for the use cases mentioned above, it’s essential to provide a comprehensive input, so-called “prompt”. The prompt should specify what needs to be done and in which context, and it should also describe how the output should look as specifically as possible.
Think twice: define both input and output
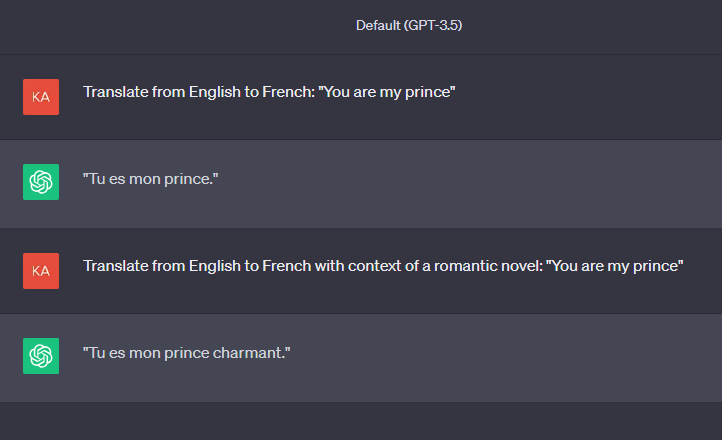
To achieve specificity in the task that should be accomplished, you can add a perspective or contextual background. For example, “proofread from the linguistic perspective”, “take the role of a professional grammar corrector”, “avoid changing meaning as much as possible”, or “identify idiomatic phrases and provide an alternative”, can be effective.
Another fundamental dimension of providing good input for ChatGPT is adding context for the translations, or any additional related information, such as terminology, guidelines, or the base text used for creating the input prompt. These could be even web pages, docs, etc. Of course, here it depends on the capabilities of your working interface with ChatGPT.
The specificity in how the output should be generated then helps with further working with the results effectively without additional steps, such as formatting or separating suggestions from explanations.
ChatGPT prompts for localization
Now the question is, how to put together these super prompts capable of producing valuable results? One thing that comes to mind is that “there must be something already”. Uncle Google can help here. Indeed, there are tons of prompt databases, and it might be good to browse through them for inspiration or to get the hang of how prompts can be constructed.
But a more potent and usually more efficient approach is creating your own prompt and iterating until you’re satisfied with the quality of results.
What should you write in the prompt?
The more descriptive and instructive your prompt is, the better the output you can expect. Here are some considerations of what a powerful prompt should include:
- Setup instructions: Provide relevant background context or foundational details about the topic, the desired tone, style, or audience. The more you can narrow down the requirements, the more tailored the response will be.
- Desired Action or Intent: Clearly state what you want ChatGPT to do. Whether it’s translating a phrase, proofreading source text, or generating creative content, be explicit about the desired action.
- Action Description and Entities: Specify any additional guidelines for the desired action. This can involve providing examples, specifying the format, or even suggesting specific words or phrases to use. The more specific you are, the more control you have over the output.
- Relevant Contextual Details: If applicable, provide any additional relevant details or circumstances that might influence the response, such as specific context for a translation task. For example, if you’re translating a phrase from a romantic novel, mentioning this specific context will impact the output generated by ChatGPT.
The key is to combine these types of information effectively. For example, Gridly provides a spreadsheet-like interface where you can input all the necessary information into columns and concatenate them into a prompt that matches your purpose. This way you can then play around with parts of the prompt and even change them dynamically.
Iterate your way to great ChatGPT results
Creating good prompts is one part of the process; equally important is testing and optimizing them for high-quality results. Run a prompt on a small but diversified sample of your content, then check the results, modify the prompt, and then run it again on a larger sample.
Within Gridly, you can use Views to facilitate these iterations. You can create a specialized view in which you’ll include records for testing ChatGPT prompts. Depending on the view filter, records can be added to a view by selecting a checkbox or by having a specific value.
Prompt engineering tactics: chain of thought
During testing, explore various tactics to ensure the best results. One effective approach is to break a complex task into smaller ones or add additional tasks that lead to better results, such as creating and analyzing alternatives. This method when you break a complex task into smaller ones is called a chain of thought.
In this case, ChatGPT is prompted to produce intermediate reasoning steps before delivering a final answer to a multi-step problem like translation. These steps can involve analyzing source text for idiomatic expressions or identifying cases where gender is not clear.
The results produced by ChatGPT can be then used as input for other prompts. In Gridly, it’s possible to have separate columns for the intermediate/reasoning steps. Additionally, the prompts can be divided into more prompts and then run consecutively within an automation workflow.
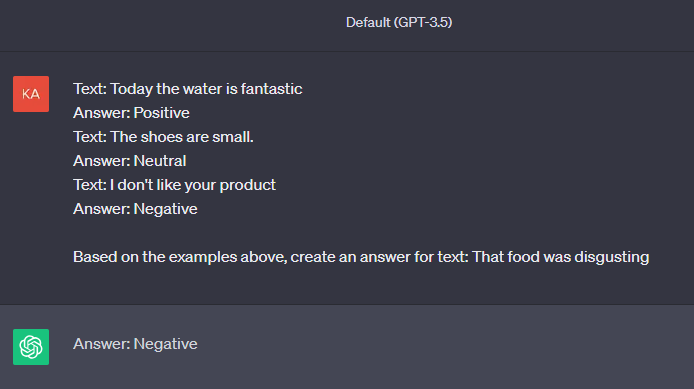
Prompt engineering tactics: few-shot prompting
Another tactic capable of yielding great results for certain use cases is using examples of the desired output within the prompt, known as few-shot prompting. Examples can be part of the prompt or retrieved from a database, document, or even a Grid in Gridly. This approach helps improve the accuracy of results as ChatGPT considers both the query and the examples.
Tuning the model: temperature and presence penalty
Using OpenAI LLMs through API instead of just the standard browser interface offers more control over the model’s behavior and enables you to leverage parameters that are handy for localization.
For example, you can set up the model’s temperature which determines whether the responses will be more creative, random, and diverse or more conservative, common, and predictable. While for creative writing or copywriting, you’ll utilize higher temperature values, for cases like grammar check, summarizing, shortening, or spell checking, you want to use lower temperature values.
Another powerful parameter is the presence penalty, which determines how closely the model adheres to the input text. Positive values encourage the model to introduce new vocabulary, while negative maintain consistency with regard to the input.
When writing a poem you might want to use a positive number for the presence penalty but for translating, you should stick with values close to the bottom limit to maintain the meaning of the original text as much as possible.
What to be careful of when using ChatGPT
While ChatGPT can be a powerful tool for generating human-like translations, there are certain areas where it’s better to think twice before using it:
-
Post-editing: Even though the results generated by ChatGPT can be pretty accurate when using it for translation and following the techniques described above, it doesn’t eliminate the need to manually review the text and ensure that everything has been translated correctly.
Include linguists in your ChatGPT localization workflow and use their corrections in the prompts, that you’ll run repeatedly on bigger and bigger chunks of text. Lack of testing and absence of correct prompting will yield poor results that will then need to be largely edited or even fully retranslated. -
Data Security: When using ChatGPT(or ChatGPT Plus) through the browser interface provided by OpenAI, data is collected and stored by default. This might create concerns about Data Security Management within your company when ChatGPT is used on your company data.
Opt-out options are available, but these are only supported for business subscriptions accessing the service through API. This is also the case of Gridly where no data is stored by default. -
Costs: Although the ChatGPT 3.5 model is currently free of charge, this applies only to access through a browser using OpenAI’s chat interface. Implementing ChatGPT, even the 3.5 model, into your workflow or existing tools means you would need to access it via API and this is paid access.
OpenAI uses a pay-as-you-go business model for all their language models which means you pay for the number of words, or more precisely tokens, in your prompt (input) and also the volume of text generated by the model (output). Therefore testing makes even more sense before applying prompts to bigger volumes of text.>> How you can convert the number of characters/words into OpenAI tokens
-
Knowledge Cut-off: ChatGPT has a knowledge cut-off and might not be up-to-date with the latest developments beyond its training data. GPT 3.5 (the current model powering ChatGPT(9/2023) is up-to-date until September 2021, while GPT 4.0 (powering the paid version ChatGPT Plus) extends until the end of 2022.
How to get started with ChatGPT
The simplest and easiest way to start with ChatGPT is to go to the basic chat interface that OpenAI provides for free and start with the initial testing of prompts on a couple of strings to get the hang of how ChatGPT works.
However, the real deal comes with using ChatGPT where your content is stored or localized to avoid moving content back and forth between and start leveraging its results in your workflow right away.
This is possible with Gridly, which gives you a convenient way to run prompts for ChatGPT or Dall-E (a model used for generating images) on selected content, collect responses in your Grids, and work with them instantly.
You can configure an action within an automation workflow that will run a desired prompt. Within the prompt, you can refer to data or content stored in Gridly to provide more context or examples. Then you just choose a column where the results should be received.
![]()
You can combine multiple actions or prompts for ChatGPT and use multiple columns to work with results. Therefore, you can leverage the chain of thought prompting method or easily separate AI-generated results from human-generated ones.
Automation workflows can be applied fully automatically or manually on a group of records (rows) that can be put together by using filters and views. Thus enabling you to test on small chunks of data and then roll out to bigger volumes when you have the confidence.
>> Learn more about how ChatGPT and Dall-E work in Gridly
Let your translators work with ChatGPT with ease
The automation workflows with ChatGPT actions triggered on selected content is a solution capable of working with large volumes of data. But what if you are a translator and want to work string by string and also leverage the help of AI?
For this purpose, Gridly offers an AI translation add-on that helps generate a particular string without the need to formulate any prompt. The prompt is already embedded in the add-on and the GPT model on the background is fine-tuned for string translations. Translators just click on the button “Translate with AI” and instantly obtain results they can use.
The add-on can also use ChatGPT to rephrase, shorten or correct your text, and come up with various suggestions. Translators can do this simply by clicking on action buttons without the need to create any prompts.
>> Learn more about AI-assisted translation
Frequently asked questions
Why is ChatGPT more useful for localization than traditional machine translation tools?
Traditional machine translation tools — including neural MT engines like Google Translate, Amazon Translate, and DeepL — translate sentence by sentence without access to surrounding context, which causes failures in gender agreement, cultural analogies, idiom handling, and tone consistency. ChatGPT and other large language models approach translation differently: they can reflect relevant literary and cultural context, consider style constraints and character limits, identify idiomatic expressions before translating them, and generate multiple alternative phrasings for a human to evaluate. The key difference is that ChatGPT requires a well-constructed prompt to deliver on this potential — a simple “translate this text” instruction will produce results no better than a standard MT engine. The value comes from giving the model the context, constraints, and step-by-step instructions it needs to engage its full language understanding.
What localization tasks can ChatGPT handle beyond direct translation?
ChatGPT’s versatility across the localization workflow is one of its most significant advantages over single-purpose MT tools. It can proofread source text and flag errors or awkward phrasing before translation begins, catching quality issues at the cheapest possible point. It can generate initial pre-translations at scale for human refinement. It can propose alternative phrasings when a first translation attempt does not satisfy length constraints or stylistic requirements. It can assist in post-editing preparation by identifying sections of translated content that are likely to need additional attention. It can generate supporting localization materials — translator briefs, context notes, product descriptions, UI copy variants. And it can run automated QA checks — spelling, grammar, missing tags, special characters, and length violations — and output findings in a format that QA teams can act on directly.
What makes a strong ChatGPT prompt for localization use cases?
Four components consistently produce better results. Setup instructions establish the context, tone, target audience, and any constraints — for example, specifying that the model should take the role of a professional linguistics editor or that it should avoid changing meaning unless the original contains a clear error. The desired action states explicitly what the model should do: translate, proofread, shorten, generate alternatives, or check QA criteria. Action description and entities add specificity — examples of preferred phrasing, the format in which results should be returned, terminology that must be used or avoided. Relevant contextual details provide any additional information that should influence the output: the genre of the source content, the character limit of the UI field, the audience demographic, or a glossary of product-specific terms. The more precisely each of these components is defined, the less post-processing the output requires.
What is chain of thought prompting and why does it improve localization output quality?
Chain of thought prompting breaks a complex task — such as translating a culturally nuanced passage — into a sequence of smaller reasoning steps that the model works through before producing its final output. Instead of asking for a translation directly, the prompt first asks the model to identify idiomatic expressions in the source text, then to analyze cases where gender is ambiguous, then to generate translation alternatives for the flagged phrases, and finally to produce the translation informed by this analysis. Each intermediate step produces reasoning output that shapes the final result. In a platform like Gridly, these intermediate steps can be stored in separate columns and used as input for subsequent prompt stages, making the chain of thought approach practical at scale rather than limited to one-off manual interactions.
What is few-shot prompting and when should localization teams use it?
Few-shot prompting adds concrete examples of the desired output directly into the prompt, so the model can calibrate its response against demonstrated expectations rather than interpreting abstract instructions alone. For localization, this is particularly powerful when enforcing a specific translation style — for example, showing the model three examples of how your product’s UI copy has been translated in the past, so the model maintains the same register, terminology, and level of formality in new strings. Examples can be embedded directly in the prompt or retrieved dynamically from a database of approved translations, making the approach compatible with existing translation memory assets. Few-shot prompting is most valuable for content types where style consistency matters most: brand copy, character dialogue, in-game UI, and customer-facing marketing content.
What are the temperature and presence penalty parameters and how should they be set for translation?
These parameters, available when accessing GPT models through the API rather than the browser interface, give teams fine-grained control over output behavior. Temperature determines how predictable or creative the model’s word choices are: lower values produce more consistent, conventional output, while higher values produce more varied and unexpected language. For translation, grammar checking, text shortening, and summarization — tasks where consistency and fidelity to the source matter most — a low temperature setting is appropriate. For creative copywriting, adapting marketing content for cultural relevance, or generating UI copy variants, a higher temperature setting produces more diverse options. The presence penalty determines how closely the model stays to the vocabulary of the input: keeping it close to zero or slightly negative for translation preserves the meaning of the original, while positive values encourage the model to introduce new vocabulary — useful for creative rewriting tasks.
Does using ChatGPT for localization eliminate the need for human post-editing?
No. Even with well-constructed prompts, thorough testing, and appropriate model parameters, ChatGPT-generated translations require human review before publication. The model can make subtle errors in meaning, produce translations that are linguistically correct but culturally off, or generate output that passes a surface reading but fails under the scrutiny of a native speaker familiar with the subject matter. The appropriate role for ChatGPT in a localization workflow is as a productivity accelerator: it handles the volume work of generating first drafts at scale, which human translators then review and refine rather than translating from scratch. The ratio of AI to human effort shifts significantly in favour of efficiency, but the human review step is not optional for content where quality matters.
What data security risks should teams be aware of when using ChatGPT for localization?
When accessing ChatGPT through OpenAI’s browser interface, input data is collected and stored by default — which creates potential conflicts with confidentiality obligations for proprietary game content, unreleased product copy, legal text, or any content covered by non-disclosure agreements. Opt-out options exist but apply only to API-based business subscriptions, not to the standard consumer interface. Teams handling sensitive content should access GPT models exclusively through the API with data storage disabled, and should review OpenAI’s data processing terms in the context of their specific contractual and regulatory obligations. Using a localization platform that integrates the API with no data stored by default — as Gridly does — removes this risk for teams already managing their content within that platform.
How much does it cost to use ChatGPT for localization via API?
API access to OpenAI’s models operates on a pay-as-you-go pricing model based on token consumption — tokens representing roughly three to four characters of text on average — with separate rates for input (the prompt) and output (the model’s response). Because localization prompts often include substantial context alongside the source string — terminology, examples, style instructions — the input token count per string can be significantly higher than the string length alone. Costs should be estimated carefully before rolling out a ChatGPT localization workflow at scale: test prompts on a representative sample, measure average token consumption per string type, and project the total cost against the volume of content to be translated. This is also why testing on small, diversified samples before committing to large batches is practical discipline rather than optional caution.
How should localization teams approach prompt testing and iteration?
Prompt development is an empirical process: no prompt is correct on the first attempt for all content types, and the quality gap between a rough initial prompt and a refined one is often significant. The recommended approach is to run a candidate prompt on a small but diverse sample — including short UI strings, longer narrative text, strings with special characters or variables, and strings from different content categories — then evaluate the output against quality criteria, modify the prompt based on what falls short, and repeat. Each iteration should improve on a specific weakness identified in the previous round. Testing on small samples before applying to large batches also limits cost exposure. Within a platform like Gridly, dedicated views can be used to isolate test records, and results can be compared across multiple columns for different prompt versions running simultaneously.
How does Gridly integrate ChatGPT into localization workflows?
Gridly integrates ChatGPT through two complementary mechanisms. For bulk, automated use cases, teams configure automation workflows in which a ChatGPT action runs a configured prompt against selected content — referencing data stored in any column as context, terminology, or examples — and writes the model’s response back to a designated output column. Multiple chained actions in a single workflow support chain of thought prompting at scale. These workflows can be triggered automatically on new or changed content or applied manually to a filtered selection of records. For translator-level string-by-string use, Gridly’s AI translation add-on embeds a pre-configured, fine-tuned prompt for string translation — translators click a single button to generate a translation, rephrase, shorten, or generate alternatives without writing any prompt themselves. In both cases, data is processed through the API with no storage by default, addressing the data security considerations that apply when using ChatGPT on proprietary localization content.
Don’t let the opportunity slip away
ChatGPT and other large language models represent an opportunity to transform localization workflows by automating time-consuming tasks, expediting turnaround times, and enhancing output quality.
When set up properly with thoughtful prompts and ample context, ChatGPT can produce high-quality machine translations with an understanding of nuance, culture, and style. The capabilities for translation, editing, QA, and more create productivity gains across the whole localization workflow.
With the right strategies, localization teams can harness this powerful AI technology to achieve significant time and cost savings.