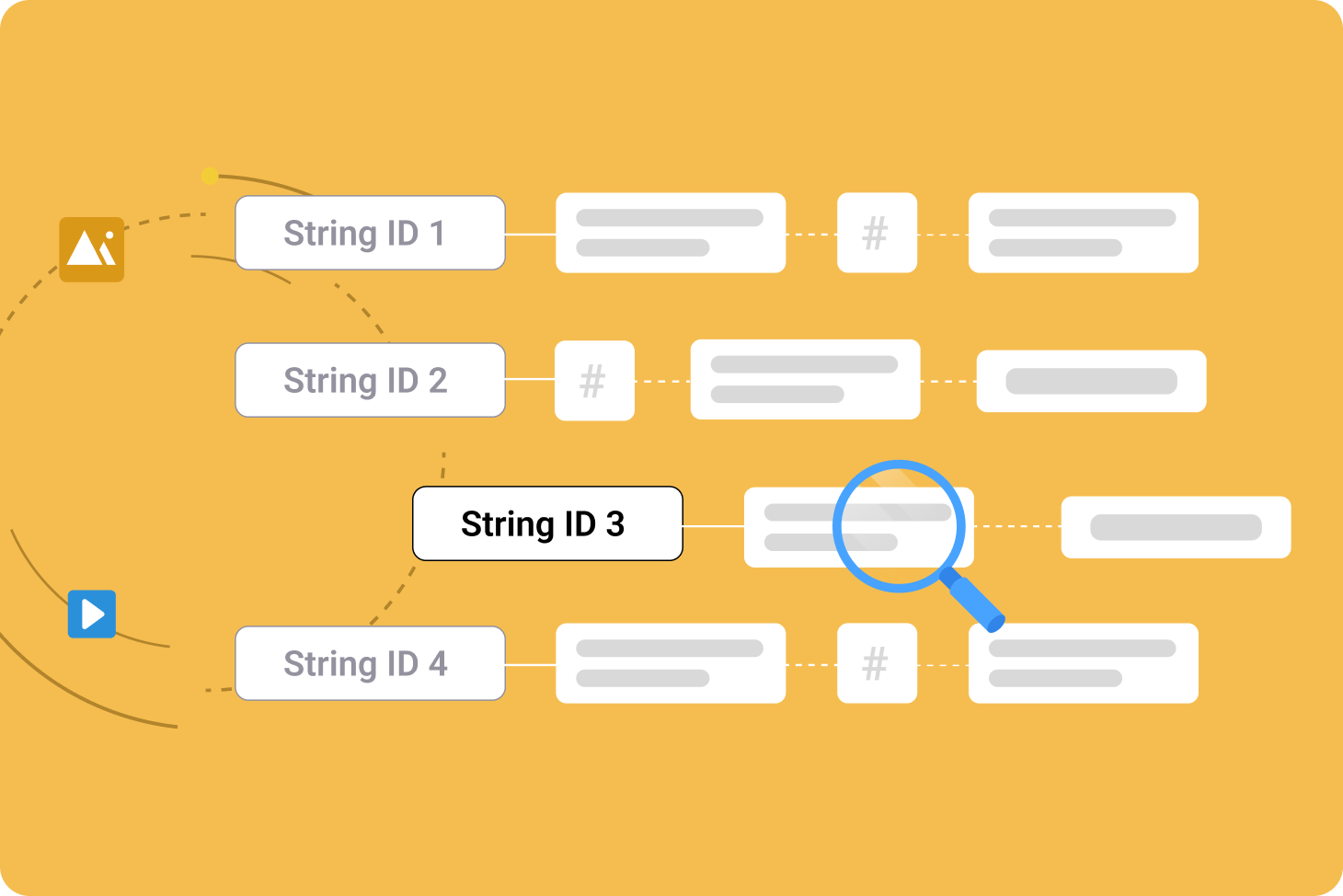
Workflow steps for a localization workflow using Github
1 - Empty source strings stored in a CSV file on GitHub

2 - Importing empty strings into Gridly via a Gridly automation

3 - Localization is performed in Gridly or in a connected platform such as like memoQ or Phrase

4 - Gridly automatically updates the source file on GitHub

5 - The commit of the source file update

Implementing the integration
While this tutorial uses Python as an example, you can use any coding language with Gridly’s API.
Importing data from GitHub into Gridly
- Find the files on GitHub
To find the CSV files on GitHub, use the tree call of a branch to return all files in all subfolders. Filter the results by files ending with .csv.
- Identify the file contents
Use the download_url value of the file to obtain its content.
- Store the file path
Gridly uses a tree system called Paths to store files in a hierarchy. Create a new column in the file content from the last step and add the Path variable of the file to every row. When we push the updated file back to GitHub, we’ll know the exact location of each file.
- Create columns in Gridly for file headers
To parse your CSV, create columns in Gridly that match your columns in the CSV. By default, Gridly creates multiple-line columns with the name and ID of your CSV column. Edit the Gridly columns as needed — for example, change the column type to Localization and select a language. This has no effect on the integration with GitHub and only serves to make content easier to find in Gridly.
- Upload the file into your Grid
CSV file import is one of the many calls you can perform with Gridly’s rich API, which can handle any action also permitted within the Gridly UI.
Code example: file import into Gridly
1import base64
2import io
3import requests
4import json
5import csv
6import re
7from io import StringIO
8
9def getFiles(github_api_key, github_owner, github_repo, github_branch):
10 url = "https://api.github.com/repos/" + github_owner + "/" + github_repo + "/git/trees/" + github_branch + "?recursive=1"
11 payload={}
12 headers = {
13 'Authorization': 'Bearer ' + github_api_key,
14 }
15 response = requests.request("GET", url, headers=headers, data=payload)
16 return json.loads(response.text)
17
18def get_file_data(github_api_key, github_owner, github_repo, file_path):
19 url = "https://api.github.com/repos/" + github_owner + "/" + github_repo + "/contents/" + file_path
20 payload={}
21 headers = {
22 'Authorization': 'Bearer ' + github_api_key
23 }
24 response = requests.request("GET", url, headers=headers, data=payload)
25 return json.loads(response.text)
26
27def readFiles(github_api_key, github_owner, github_repo, github_branch, viewId, apiKey):
28 repo_files = getFiles(github_api_key, github_owner, github_repo, github_branch)
29 headers = {
30 'X-GitHub-Api-Version': '2022-11-28',
31 'Authorization': 'Bearer ' + github_api_key
32 }
33 for repo_file in repo_files\['tree']:
34 if repo_file\['path'].endswith('.csv'):
35 valid_file = get_file_data(github_api_key, github_owner, github_repo, repo_file\['path'])
36 url = valid_file\['download_url']
37 req = requests.get(url, headers=headers)\
38 print(url)
39 print(req)
40 if req.status_code == requests.codes.ok:
41 generate_columns(viewId, apiKey, req.text)
42 cs_with_path = add_pathtag_to_csv(req.text, valid_file\['path'])
43 upload_file_into_gridly(cs_with_path, viewId, apiKey)
44 else:
45 print('Content was not found.')
46
47def add_pathtag_to_csv(csv_string, path):
48 # Parse the CSV string into a list of rows
49 rows = list(csv.reader(csv_string.splitlines()))
50 firstRow = True
51 # Add a new column with the value 7 for all rows
52 for row in rows:
53 if firstRow:
54 row.append('_pathTag')
55 firstRow = False
56 else:
57 row.append(path)
58 # Generate a new CSV string with the modified rows
59 modified_csv_string = "\n".join(\["\t".join(row) for row in rows])
60 return modified_csv_string
61
62def upload_file_into_gridly(file_content, viewId, apiKey):
63 url = "https://api.gridly.com/v1/views/"+viewId+"/import"
64 payload={}
65 files=\[
66 ('file',('Test Database NS_MT Post Edit_Default view.csv',file_content,'text/csv'))
67 ]
68 headers = {
69 'Authorization': 'ApiKey ' + apiKey
70 }
71 response = requests.request("POST", url, headers=headers, data=payload, files=files)
72
73def generate_columns(view_id, apiKey, csv_file):
74 reader = csv.DictReader(csv_file.splitlines())
75 # Get the headers
76 headers = reader.fieldnames
77
78```
79for header in headers:
80 url = "https://api.gridly.com/v1/views/"+view_id+"/columns"
81 id = re.sub('[^0-9a-zA-Z]+', '*', header)
82 payload = json.dumps({
83 "id": id,
84 "isTarget": True,
85 "name": header,
86 "type": "multipleLines"
87 })
88 headers = {
89 'Authorization': 'ApiKey ' + apiKey,
90 'Content-Type': 'application/json'
91 }
92
93 response = requests.request("POST", url, headers=headers, data=payload)
94```
95
96def get_files_from_github(event, context):
97 gridly_api_key = event\["gridly_api_key"]
98 view_id = event\["view_id"]
99 github_owner = event\["github_owner"]
100 github_token = event\["github_token"]
101 github_repo = event\["gitub_repo"]
102 github_branch = event\["github_branch"]
103 readFiles(github_token, github_owner, github_repo, github_branch, view_id, gridly_api_key)Push translated files back into GitHub
- Export Grid as CSV from Gridly
Export the whole Grid from Gridly in CSV format via the Gridly API export endpoint.
- Split files by Path
Split the Grid data by Path to organize files as needed.
- Get the file SHA on GitHub
The original file SHA is needed for the commit call. In this tutorial, we’re using a function that requires the file path to retrieve the data object of the file from GitHub. Then, we can use the returned data to commit the updated data.
- Delete unnecessary headers from the CSV
Since the Path column isn’t present in the original file, remove it from the data collection commiting to GitHub.
- Commit the updated and cleaned data
In the response body, provide the SHA of the original file and the content decoded as byte64 in UTF-8 format.
Code example: pushing the changes back to GitHub
1import base64
2import io
3import requests
4import json
5import csv
6from io import StringIO
7
8def export_file_from_gridly(view_id, apikey):
9 url = "https://api.gridly.com/v1/views/" + view_id + "/export"
10 payload={}
11 headers = {
12 'Authorization': 'ApiKey ' + apikey
13 }
14
15```
16response = requests.request("GET", url, headers=headers, data=payload)
17return response.text
18```
19
20def split_csv_by_path(csv_string):
21 reader = csv.DictReader(csv_string.splitlines())
22 rows = list(reader)
23
24```
25# Create a dictionary of lists, with one list for each unique value in the given column
26csv_dict = {}
27for row in rows:
28 if row['_pathTag'] not in csv_dict:
29 csv_dict[row['_pathTag']] = [row]
30 else:
31 csv_dict[row['_pathTag']].append(row)
32
33# Write each list of dictionaries to a separate CSV string
34csv_strings = {}
35fieldnames = ['English', 'Swedish', 'Vietnamese', '_recordId', '_pathTag']
36
37for name, rows in csv_dict.items():
38 # Use a StringIO object to write the CSV to a string
39 sio = StringIO()
40 writer = csv.DictWriter(sio, fieldnames=fieldnames, delimiter="\t")
41 writer.writeheader()
42 writer.writerows(rows)
43 csv_strings[name] = sio.getvalue()
44return csv_strings
45```
46
47def delete_not_needed_headers(csv_string):
48 csv_string_io = io.StringIO(csv_string)
49 reader = csv.DictReader(csv_string_io, delimiter='\t')
50 rows = \[row for row in reader]
51 column_to_delete = '_pathTag'
52 for row in rows:
53 del row\[column_to_delete]
54 output_string = io.StringIO()
55 writer = csv.DictWriter(output_string, fieldnames=list(rows\[0].keys()))
56 writer.writeheader()
57 for row in rows:
58 writer.writerow(row)
59 return output_string.getvalue()
60
61def fetch_to_github_steps(github_api_key, github_owner, github_repo, view_id, api_key):
62 files = split_csv_by_path(export_file_from_gridly(view_id, api_key))
63 for name, csv_string in files.items():
64 csv_string = delete_not_needed_headers(csv_string)
65 file_data = get_file_data(github_api_key, github_owner, github_repo, name)
66 commit_to_github(github_api_key, github_owner, github_repo, name, csv_string, file_data\['sha'])
67
68def commit_to_github(github_api_key, github_owner, github_repo, file_path, content, sha):
69 url = "https://api.github.com/repos/"+github_owner+"/" + github_repo + "/contents/" + file_path
70 content = base64.b64encode(bytes(content, 'utf-8'))
71 print(content)
72 payload = json.dumps({
73 "message": "Update from Gridly",
74 "content": content.decode('utf-8'),
75 "sha": sha
76 })
77 headers = {
78 'Authorization': 'Bearer ' + github_api_key,
79 'Content-Type': 'application/json'
80 }
81
82```
83response = requests.request("PUT", url, headers=headers, data=payload)
84print(response.text)
85```
86
87def commit_files_to_github(event, context):
88 gridly_api_key = event\["gridly_api_key"]
89 view_id = event\["view_id"]
90 github_owner = event\["github_owner"]
91 github_token = event\["github_token"]
92 github_repo = event\["gitub_repo"]
93 github_branch = event\["github_branch"]
94 fetch_to_github_steps(github_token, github_owner, github_repo, view_id, gridly_api_key)Authorization
GitHub
GitHub requires an API key to get and set data. In our examples, we’ve used the github_token variable to store that token. Here’s how to obtain your GitHub token:
- On GitHub, click your avatar in the top-right corner and select Settings.
- In the left sidebar, click Developer settings.
- Click on Personal access tokens.
- Click Generate new token.
- Give your token a descriptive name, select its scopes (permissions), then click Generate token. Select the repo option to give permission for your private and public repositories.
Treat your API token like a password, as it allows access to your GitHub account and data. Grant only the minimum permissions necessary for the desired task.
Gridly
To use the Gridly Rest API, open the Grid that you’ll use for the connection. In the API section, you’ll find viewID and API key for your Grid.
Set up AWS Lambda functions in Gridly
As seen in the code examples, base calls initiate the whole process in both directions. The arguments of these base calls are event and context. The Gridly lambda script places the payload into the event argument.
How to create an automation in Gridly
- Open your Grid and click the lightning-bolt Automations icon on the right side.
- Click Add automation.
- Name your automation.
- Click Add Trigger.
- Select the Trigger button clicked from the list.
- Click Add Step.
- Click Lambda Function.
- Click Add Function.
- Browse the ZIP file that contains the script.
- Fill the form with the required data. Set the Handler name as the name of the function. In the sample code in this tutorial, the handler name is get_files_from_github.
- Click Add.
- Create a JSON payload in the payload section with the following data:
{
“gridly_api_key”:"",
“view_id”:"",
“github_owner”:"",
“gitub_repo”:"",
“github_branch”:"",
“github_token”:""
}
``
The gridly_api_key and view_id can be found in Gridly in the API Quickstart:
The github_owner and github_repo can be found in the link of your GitHub repository. Consider the following repo link: https://github.com/norbertszolnoki/gridly-github-integration-testfiles. Here, norbertszolnoki is the owner and gridly-github-integration-testfiles is the repository.
The github_branch is a branch you would like to pull. Select main every repo has a main when they are created. For the github_token, refer to the Authorization/GitHub section of this tutorial.
Pushing the data back into GitHub uses the same payload. Enter commit_files_to_github for the Handler name when creating the action.
Expanding this script
If you have images or voice-overs in your GitHub repository, you can pull them into Gridly as well. Add an extra payload item that tells the script the header of the column containing the name of those files, and another payload item with the path of the files. Then, add a function that gets the files after the CSV import and adds them to the Grid: https://www.gridly.com/docs/api/#upload-file.