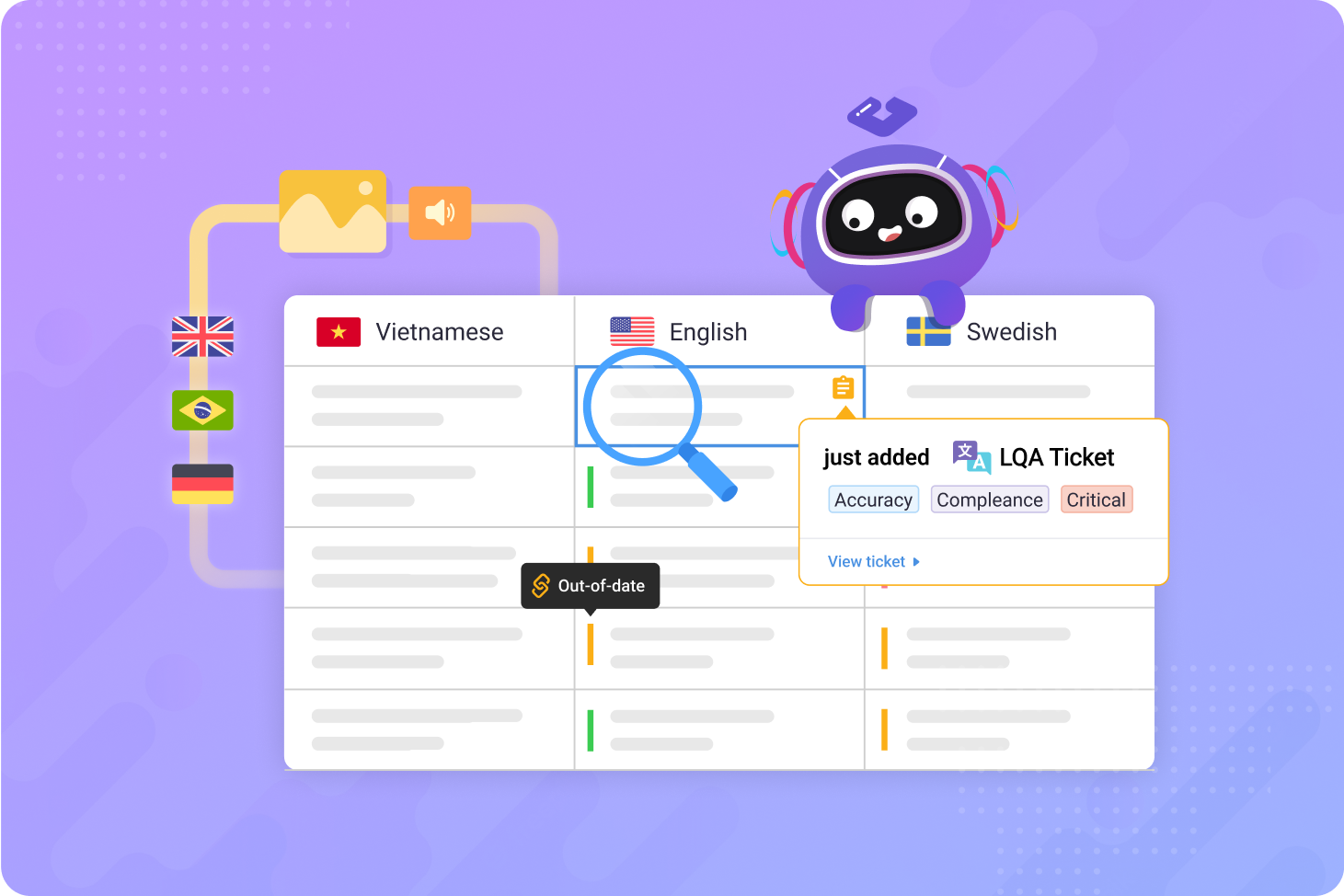
What’s covered
- What is AI-assisted game LQA and how does it differ from traditional quality assurance?
- How does AI improve game LQA workflows and reduce review time?
- What are the key AI technologies used in game LQA?
- What are the limitations of AI in game LQA and when do you need human expertise?
- Frequently asked questions about AI-assisted game LQA
- Conclusion
The localization quality assurance process for games has traditionally been one of the most time-consuming and resource-intensive stages of game development. Large-scale games require hundreds of hours of manual linguistic review across multiple languages, often delaying release schedules and inflating budgets. The game localization services market reached $2.5 billion in 2024 and is projected to grow to $7.1 billion by 2033, reflecting the increasing investment in quality localization processes. As live service games demand faster content updates and mobile titles race to capture emerging markets, development teams are increasingly turning to AI-assisted LQA solutions to maintain quality while accelerating delivery timelines.
AI-assisted game LQA combines machine learning algorithms with traditional quality assurance workflows to automatically detect translation errors, inconsistencies, and cultural issues before human reviewers examine the content. This approach doesn’t replace linguistic experts but augments their capabilities, allowing QA teams to focus on context-dependent issues, creative adaptation, and player experience rather than catching basic grammatical errors or terminology mismatches. Learn more about the benefits and considerations in our guide to automated localization QA.
This guide examines how AI technologies are reshaping game localization quality assurance, what implementation strategies work for different studio sizes, and where human expertise remains irreplaceable in the quality assurance process.
What is AI-assisted game LQA and how does it differ from traditional quality assurance?
AI-assisted game LQA uses machine learning algorithms to automatically identify translation errors, terminology inconsistencies, and quality issues in localized game content before human reviewers conduct final verification. Unlike traditional manual review processes where linguists examine every string sequentially, AI systems can instantly flag problematic translations based on learned patterns, context analysis, and quality metrics.
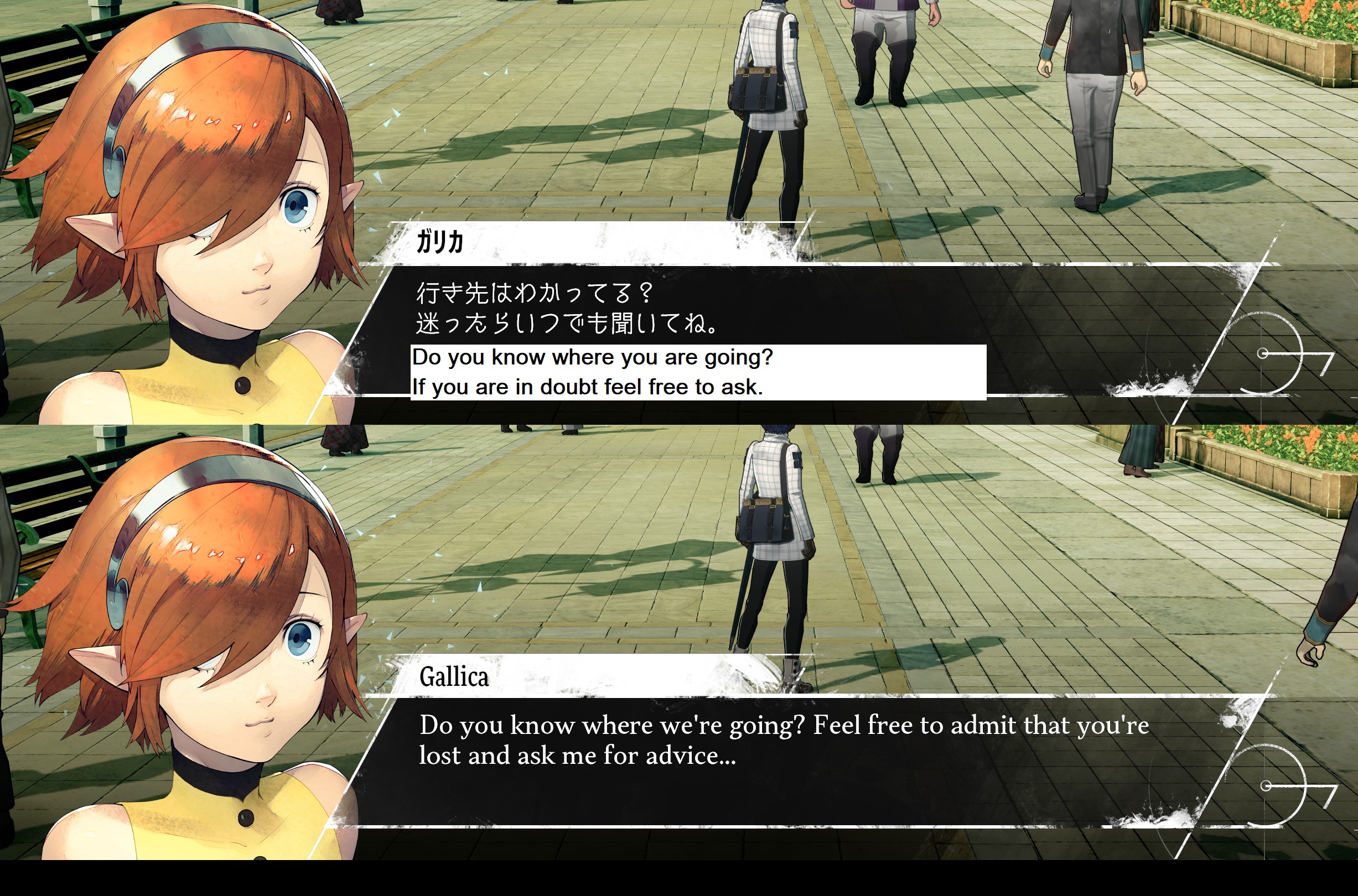
Traditional game LQA follows a linear workflow: translators deliver completed content, linguistic reviewers check every string for accuracy and style, functional testers verify in-game implementation, and stakeholders approve final builds. This process typically requires multiple review cycles for complex titles, with each iteration taking several weeks depending on content volume and language count.
AI-assisted LQA transforms this workflow by introducing automated pre-screening:
- Automated error detection. Machine learning models identify grammatical mistakes, syntax errors, and formatting issues instantly across all target languages.
- Contextual consistency checks. AI systems compare new translations against existing terminology databases, previously translated content, and glossaries to flag inconsistencies.
- Cultural sensitivity screening. Natural language processing models detect potentially offensive terms, cultural references that don't translate, and region-specific compliance issues.
- Quality scoring. Algorithms assign confidence scores to each translation, prioritizing low-scoring strings for human review.
The key difference lies in resource allocation. Traditional LQA requires human reviewers to examine all content regardless of quality level, spending significant time on straightforward translations that contain no errors. AI-assisted approaches allow linguistic teams to concentrate exclusively on strings flagged by automated systems, complex narrative content, and culturally nuanced material that requires human judgment.
For example, studios implementing AI-assisted quality checks have reported significant reductions in initial review time for game expansions, allowing linguists to allocate more time to narrative consistency and character voice rather than basic error detection.
How does AI improve game LQA workflows and reduce review time?
AI significantly reduces game LQA review time through automated pre-screening that identifies obvious errors, inconsistencies, and quality issues before human reviewers examine the content. According to a 2024 industry study, businesses using AI-driven localization saw a 60% increase in content delivery speed compared to traditional workflows. This acceleration comes from parallel processing capabilities, instant terminology verification, and intelligent prioritization that directs human expertise toward high-value review tasks.
Automated error detection at scale
Machine learning models trained on millions of translation pairs can instantly identify common error patterns across multiple languages simultaneously. While human reviewers can examine hundreds of strings per hour, AI systems process thousands of strings per second, flagging:
- Grammatical errors. Subject-verb disagreement, incorrect tense usage, and syntax violations.
- Formatting issues. Missing placeholders, broken HTML tags, incorrect variable syntax, and formatting code errors.
- Length violations. Translations that exceed character limits for UI elements, subtitle timing, or text box constraints.
- Numeric inconsistencies. Mismatched numbers, dates, currencies, and measurement units between source and target text.
This parallel processing capability proves particularly valuable for live service games requiring rapid content updates. Games releasing frequent events across multiple languages use AI-assisted LQA to maintain quality standards while meeting aggressive deployment schedules that would be impossible with purely manual review processes.
Terminology consistency enforcement
Game franchises develop extensive terminology databases containing thousands of character names, location references, item descriptions, and universe-specific terms that must remain consistent across all content. AI systems can instantly verify every string against these glossaries, flagging any deviation from established terminology:
- Character name variations. Detecting when "Geralt" appears as "Gerald" or when Japanese name orders switch between Western and Eastern conventions.
- Item terminology drift. Identifying when "Health Potion" becomes "Healing Elixir" in new content, breaking established player expectations.
- Franchise-specific vocabulary. Ensuring made-up words, spell names, and lore terms maintain exact spelling and capitalization across all instances.
Major game franchises maintain extensive terminology databases containing thousands of franchise-specific terms. AI-assisted LQA systems cross-reference every translation against these databases, automatically flagging any string containing term variations before human reviewers examine the content.
Intelligent prioritization and quality scoring
Not all translations require equal scrutiny. AI systems assign confidence scores to each translated string based on complexity, context importance, and potential quality issues. This scoring allows localization managers to allocate review resources strategically:
High-priority strings for immediate human review:
- Story-critical dialogue and narrative content.
- Player-facing UI text with high visibility.
- Tutorial instructions and onboarding content.
- Strings with low AI confidence scores.
- Content containing cultural references or idioms.
Low-priority strings suitable for spot-checking:
- Repetitive system messages.
- Debug text and error codes.
- Backend strings with minimal player visibility.
- Previously reviewed content with minor updates.
This prioritization particularly benefits indie studios with limited localization budgets. Rather than conducting comprehensive review across all content, teams can focus human expertise on player-facing strings while accepting higher risk for internal system messages that rarely surface during gameplay.
Pattern learning from previous projects
AI models improve with each project, learning from corrections made by human reviewers. When a linguist corrects a specific error type repeatedly, the system begins flagging similar patterns automatically in future content. This continuous learning means LQA accuracy increases over time without requiring additional human training:
- Studio-specific style preferences. Learning whether your team prefers formal or casual tone, how you handle gender-neutral language, and regional dialect choices.
- Recurring error patterns. Identifying common mistakes made by specific translation vendors or machine translation systems.
- Context-dependent rules. Understanding when literal translations work versus when creative adaptation is necessary based on historical review decisions.
How AI-assisted LQA reduces localization costs
The cost savings from AI-assisted LQA stem from multiple efficiency gains that compound throughout the localization workflow. Studios implementing these systems report measurable budget reductions across several areas:
Reduced human review hours:
According to industry research, automation cuts localization costs by 40–50% through reduced dependency on human translators for repetitive tasks. Linguistic reviewers who previously spent hours catching basic formatting errors, placeholder syntax mistakes, and terminology inconsistencies can now focus exclusively on high-value tasks like narrative coherence and cultural adaptation. This shift means studios pay for fewer total review hours while maintaining or improving quality standards.
Faster time-to-market:
Accelerated review cycles enable earlier game releases and content updates, directly impacting revenue potential. Live service games releasing seasonal events can reduce localization timelines from weeks to days, capturing market windows that would otherwise be missed. Machine Translation Post-Editing (MTPE) offers 30–50% cost reduction while maintaining human-level accuracy when properly implemented, demonstrating the economic viability of hybrid human-AI approaches.
Lower revision costs:
AI systems catch errors before they propagate through the QA pipeline, reducing expensive rework cycles. When issues are identified during initial automated screening rather than after functional testing or player feedback, studios avoid costs associated with:
- Re-translation of flagged content.
- Additional rounds of linguistic review.
- Engineering time for implementing corrections.
- Delayed release schedules that affect marketing plans.
Reduced project overhead:
Automated quality checks minimize coordination overhead between translation vendors, localization managers, and development teams. Rather than managing multiple review iterations across dozens of languages, project managers can focus resources on content flagged by AI systems, streamlining communication and reducing administrative burden.
What are the key AI technologies used in game LQA?
Game LQA systems primarily use neural machine translation (NMT) quality estimation, natural language processing (NLP) for error detection, and large language models (LLMs) for contextual analysis. Each technology addresses specific quality assurance challenges, and mature implementations combine multiple AI approaches to achieve comprehensive coverage. At the 2024 Conference on Machine Translation (WMT24), Claude 3.5 Sonnet won 9 out of 11 tested language pairs as the top performer, demonstrating that modern LLMs have reached near-human translation quality for many language combinations.
Neural machine translation quality estimation
NMT quality estimation models predict translation accuracy without comparing against human-created reference translations. These models analyze source-target sentence pairs and assign quality scores based on:
- Adequacy. Whether the translation conveys all information from the source text.
- Fluency. Whether the target text reads naturally in the target language.
- Semantic similarity. How closely the meaning matches between source and target.
Modern quality estimation systems like Unbabel’s OpenKiwi framework achieve correlation scores of 0.65 with human quality assessments, meaning they can reliably identify problematic translations before human review. For game localization, quality estimation proves particularly valuable for:
- Vendor comparison. Automatically evaluating translation quality across multiple vendors to identify which providers consistently deliver higher-quality output.
- Machine translation post-editing prioritization. Flagging machine-translated strings that need human revision versus those acceptable for direct publication.
- Regression testing. Detecting quality degradation when updating previously translated content or changing translation vendors.
Natural language processing for error detection
NLP models analyze linguistic structure to identify specific error types that compromise translation quality. Game-focused NLP systems typically include:
Grammar and syntax checking:
- Part-of-speech tagging to verify correct word order and grammatical structure.
- Dependency parsing to ensure phrases relate correctly within sentences.
- Morphological analysis for languages with complex grammatical cases, genders, and conjugations.
Terminology and consistency verification:
- Named entity recognition to identify proper nouns, character names, and location references.
- Semantic similarity comparison between glossary entries and actual translations.
- Cross-reference checking across related strings (e.g., quest descriptions and objective text).
Formatting and technical validation:
- Regular expression matching for placeholder syntax, formatting codes, and variable names.
- HTML/XML tag validation to ensure markup remains intact in translated strings.
- Character encoding verification to prevent mojibake and rendering issues.
Major game studios have developed NLP-based quality checkers that validate dozens of different error types automatically, including complex patterns like plural form consistency across multiple related UI strings and correct capitalization for title case in European languages.
Large language models for contextual analysis
Recent advances in LLMs enable more sophisticated quality checks that consider broader context beyond individual strings. GPT-4, Claude, and similar models can:
- Evaluate tone consistency. Determining whether translated dialogue maintains appropriate formality levels, character personality, and emotional intent.
- Assess cultural appropriateness. Identifying references, metaphors, or idioms that don't translate effectively to target cultures.
- Verify narrative coherence. Checking whether character names, plot references, and story elements remain consistent across multiple dialogue exchanges.
- Generate alternative suggestions. Proposing multiple translation options when existing translations seem problematic, giving human reviewers concrete alternatives to consider.
LLM-based analysis excels at catching subtle issues that traditional NLP models miss. For example, a character consistently using informal language suddenly switching to formal speech in a single line might be grammatically correct but narratively inconsistent. LLMs can flag these tone breaks that simpler algorithms overlook.
However, LLMs also present challenges for game LQA:
- Hallucination risks. Models may confidently suggest changes that introduce errors rather than fixing them.
- Inconsistent performance across languages. LLMs trained primarily on English perform significantly worse on lower-resource languages common in game localization.
- High computational costs. Processing hundreds of thousands of game strings through LLM analysis requires substantial infrastructure investment.
Computer vision for in-context quality assurance
Advanced LQA systems incorporate computer vision models that analyze how translations appear within actual game interfaces. These systems:
- Detect text overflow and truncation. Identifying when translated text exceeds button boundaries, text boxes, or dialogue windows.
- Verify visual coherence. Ensuring translated UI elements maintain readability against background colors, textures, and animations.
- Catch localization bugs. Spotting issues like text rendering outside intended areas, overlapping with other UI elements, or displaying with incorrect fonts.
Some studios use computer vision-based testing for their MMO expansions, automatically capturing screenshots of translated strings in-game and flagging visual issues before human testers conduct full playthrough reviews.
What are the limitations of AI in game LQA and when do you need human expertise?
AI-assisted LQA cannot evaluate creative adaptation, cultural nuance, or context-dependent translation choices that make localized games feel native to target markets rather than mechanically translated. While AI excels at catching technical errors and terminology inconsistencies, it lacks the cultural knowledge and player perspective necessary for assessing whether translations actually resonate with target audiences.
Cultural context and localization strategy
Machine learning models struggle with cultural adaptation decisions that depend on deep cultural knowledge and strategic localization philosophy. Examples where human expertise remains essential:
Reference and allusion adaptation:
- When source content references Western pop culture, sports, or historical events unfamiliar to target audiences.
- Deciding whether to preserve references for educational value versus replacing with culturally equivalent alternatives.
- Maintaining author intent while ensuring target players understand the reference.
For example, Persona 5 Royal contains numerous Japanese cultural references, wordplay, and seasonal events. The English localization team made strategic decisions about which elements to preserve (maintaining Japanese honorifics for cultural authenticity) versus which to adapt (changing food references to items recognizable to Western players). AI systems cannot make these strategic calls that fundamentally shape player experience.
Tone and formality levels:
- Languages with complex formality systems (Japanese keigo, Korean jondaenmal) require understanding social hierarchies and relationship dynamics.
- Determining appropriate formality for character relationships, social contexts, and narrative moments.
- Maintaining consistency in formality choices across thousands of dialogue lines.
Regional variation and dialect choices:
- Deciding whether to use neutral language versus regional dialects for character differentiation.
- Balancing authenticity with accessibility when representing accent or speech patterns.
- Ensuring regional choices don't create stereotypes or offensive implications.
Creative writing and narrative consistency
Game localization often requires creative adaptation rather than literal translation, particularly for dialogue, character voice, and narrative content. AI systems cannot:
Maintain character personality across translations:
- Ensuring sarcastic characters remain witty, not just grammatically translated.
- Preserving speech patterns, verbal tics, and linguistic quirks that define character identity.
- Adapting humor to work in target languages while maintaining character voice.
The Witcher 3 features distinct personalities for characters like Geralt (dry wit, minimal emotion) and Dandelion (flowery, theatrical). Human translators adapted dialogue to preserve these personalities in 15 languages, making strategic word choices that convey character even when literal translations wouldn’t capture the intended personality. AI quality checks might flag these creative adaptations as deviations from source text despite them being superior translations.
Handle wordplay, puns, and linguistic creativity:
- Recognizing when source content contains intentional wordplay requiring creative adaptation.
- Developing equivalent puns or linguistic humor that works in target languages.
- Knowing when to sacrifice literal meaning to preserve comedic effect.
Assess narrative coherence and emotional impact:
- Evaluating whether translated dialogue flows naturally in conversation sequences.
- Determining if emotional moments land with appropriate impact.
- Ensuring plot reveals, twists, and dramatic moments maintain intended effect.
Player experience and usability
AI systems analyze text in isolation, but game translations must function within interactive experiences:
UI and menu usability:
- Whether menu navigation feels intuitive with translated labels.
- If instructional text clearly communicates complex game systems.
- Whether button prompts and control schemes remain understandable.
Tutorial clarity and player onboarding:
- Whether translated tutorial instructions effectively teach game mechanics.
- If help text provides genuinely useful information versus confusing explanations.
- Whether new players can understand core systems from localized content.
Accessibility and inclusive language:
- Ensuring translations work for players with different reading levels.
- Avoiding unnecessarily complex vocabulary when simpler terms suffice.
- Making strategic choices about gender-neutral language, inclusive phrasing, and representation.
Edge cases and unusual content
Game content includes numerous special cases that AI systems handle poorly:
Made-up words and fictional terminology:
- Character names, location names, and invented vocabulary without real-world references.
- Ensuring consistency in how fictional terms are rendered across languages (transliteration, translation, preservation).
Interpolated and dynamic text:
- Strings containing multiple variables that change based on player actions.
- Ensuring grammatical correctness across all possible variable combinations.
- Handling languages with complex agreement rules when variables include gendered nouns or plural forms.
Audio sync and subtitle timing:
- Evaluating whether subtitle length works for voice-over timing.
- Assessing if translated dialogue can be performed within animation constraints.
- Balancing subtitle readability with maintaining sync to voice performance.
The optimal human-AI collaboration model
Effective AI-assisted LQA treats AI as a tool that enhances human capabilities rather than replacing human judgment:
AI handles:
- Technical error detection (formatting, placeholders, syntax).
- Terminology consistency verification.
- Quality scoring and prioritization.
- Repetitive checks across thousands of strings.
- Statistical pattern identification.
Humans handle:
- Creative adaptation and cultural localization.
- Narrative consistency and character voice.
- Strategic decisions about localization philosophy.
- Edge case evaluation and unusual content.
- Final approval based on player experience considerations.
This division allows localization teams to process larger content volumes while maintaining quality standards. Rather than replacing linguistic reviewers, AI systems enable them to focus expertise where it creates the most value — improving player experience through culturally resonant, engaging translations rather than catching basic errors that machines detect more efficiently.
Frequently asked questions about AI-assisted game LQA
How accurate is AI at detecting translation errors compared to human reviewers?
AI systems excel at catching technical errors with very high accuracy (placeholder syntax, formatting issues, character limits) but achieve lower accuracy for linguistic errors requiring judgment like awkward phrasing, unnatural word choice, or tone inconsistency. Translation accuracy research shows that translations from English to Spanish achieve up to 94% accuracy with modern AI systems, while less common language pairs experience lower rates. The combination of AI pre-screening plus human review typically catches more total errors than human-only review processes that suffer from reviewer fatigue and inconsistent attention.
Does AI-assisted LQA work equally well across all languages?
No. AI quality estimation and error detection perform significantly better on high-resource languages like English, French, Spanish, German, and Simplified Chinese than on lower-resource languages like Thai, Vietnamese, Arabic, or Hebrew. The accuracy gap can be substantial between best- and worst-supported languages. Studios localizing to diverse language sets should implement language-specific quality thresholds rather than applying universal confidence scores across all targets.
Can AI-assisted LQA completely replace human linguistic reviewers?
No. AI cannot evaluate creative adaptation, cultural appropriateness, narrative consistency, or player experience quality — the elements that separate competent translations from excellent localizations. Current AI implementations significantly reduce human review time but cannot replace human judgment for content quality assessment. Studios attempting fully automated LQA consistently report quality issues in released content, particularly for narrative-driven games where player experience depends heavily on localization quality.
What’s the typical ROI timeline for implementing AI-assisted LQA?
Most studios see positive ROI within several major content releases for live service games or within a couple of years for premium titles with less frequent updates. Initial implementation requires several months of setup, configuration, and team training. Time savings accelerate as AI models learn from reviewer corrections and terminology databases expand. However, ROI depends heavily on content volume — studios localizing smaller volumes annually may not justify the implementation investment.
How do you prevent AI quality systems from rejecting valid creative translations?
Configure quality scoring to flag potential issues rather than auto-reject translations. Implement reviewer override capabilities that allow human experts to approve strings despite AI warnings, with a requirement to document reasoning. Train AI models on your historical review decisions including accepted creative adaptations, not just error corrections. Set up separate quality thresholds for narrative content versus UI strings, giving translators more creative freedom where it matters most for player experience.
What happens when AI suggestions conflict with translator decisions?
Human translators should always have final authority over translation choices, with AI systems providing recommendations rather than requirements. Effective implementations present AI feedback as “potential issues to review” rather than “corrections to implement.” Track cases where translators consistently override AI suggestions in specific contexts — this data indicates areas where AI models need additional training or where your quality rules require adjustment to accommodate valid creative choices.
How much does AI-assisted LQA cost compared to traditional quality assurance?
Platform costs vary widely depending on features, content volume, and language count. However, reduced human review time typically generates significant savings in linguistic quality assurance costs. Industry research indicates that automation cuts localization costs by 40–50% through reduced dependency on human translators for repetitive tasks, often resulting in net savings overall despite tool expenses. For studios with substantial annual localization budgets, ROI usually justifies implementation. Smaller projects benefit from platforms with usage-based pricing rather than high fixed monthly costs.
Can AI-assisted LQA handle DLC, updates, and live service content differently from base game localization?
Yes. Advanced systems can apply different quality thresholds based on content type, update priority, and release timeline. Configure more lenient automated approval for time-sensitive seasonal events while maintaining stricter human review requirements for story expansion content. Leverage translation memory and terminology databases built during base game localization to accelerate quality checks for updates — strings similar to previously approved content can often proceed with minimal review.
Conclusion
AI-assisted game LQA represents a practical evolution in localization workflows rather than a revolutionary replacement for human expertise. Studios implementing AI quality checks successfully focus on augmenting human capabilities — catching obvious errors automatically, prioritizing complex content for linguistic review, and freeing experts to concentrate on creative adaptation and player experience rather than mechanical error detection.
The technology works best when implemented incrementally: start with automated technical validation, add terminology verification, introduce quality scoring, and layer in advanced contextual analysis only after foundational systems prove reliable. Attempting to deploy comprehensive AI systems immediately typically overwhelms teams with false positives and undermines trust in AI recommendations.
Current AI limitations remain significant. Machine learning models cannot evaluate cultural appropriateness, assess narrative consistency, or determine whether translations actually resonate with players — the qualities that separate competent localization from excellent player experiences. Studios seeking to maintain premium quality standards will continue relying on experienced linguistic reviewers for final approval, with AI serving as an efficiency multiplier rather than a replacement.
For live service games with aggressive content schedules and substantial localization budgets, AI-assisted LQA delivers measurable ROI through accelerated review cycles and reduced linguistic overhead. The global localization industry reached $71.7 billion in 2024 and continues growing at 7% annually, with AI-powered quality assurance tools becoming essential infrastructure for studios competing in international markets. Implementing a comprehensive localization QA tool that combines automated validation with human expertise enables studios to scale their quality assurance processes efficiently. Indie studios and smaller projects should carefully evaluate whether implementation effort justifies time savings given their content volume and update frequency.
The localization teams seeing greatest success treat AI quality tools as collaborative partners — systems that flag potential issues, suggest improvements, and handle repetitive verification tasks while humans focus expertise on translation choices that materially impact player experience. This human-AI collaboration model will likely define game localization quality assurance for the foreseeable future as AI capabilities continue advancing without fully replacing human judgment.
Author

Quang Pham
Quang has spent the last 5 years as a UX and technical writer, working across both B2C and B2B applications in global markets. His experience translating complex features into clear, user-friendly content has given him a deep appreciation for how localization impacts product success.
When he's not writing, you'll likely find him watching Arsenal matches or cooking.